CPU Scheduling¶
约 2542 个字 6 行代码 17 张图片 预计阅读时间 13 分钟
这一章的笔记很大一部分是在 HabbitQia 学长的笔记基础上增改的
CPU Scheduling¶
Definition: The decisions made by the OS to figure out which ready processes/threads should run and for how long.
谁用?用多久?
-
The policy is the scheduling strategy
怎么选择下一个要执行的进程。
-
The mechanism is the dispatcher
怎样快速地切换到下一个进程。
CPU-I/O Burst Cycle¶
-
I/O-bound process
主要是等 I/O。大部分的操作都是 I/O-bound 的。
e.g.
/bin/cp -
CPU-bound process
主要是等 CPU。
e.g. 科学计算(如把圆周率计算后一百万位),渲染

The CPU Scheduler¶
Selects from among the processes in memory that are ready to execute, and allocates the CPU to one of them.
当 CPU 空闲时,从所有的 ready processes 中选一个继续跑。
-
Non-preemptive scheduling: a process holds the CPU until it is willing to give it up.
非抢占式,它一直占着 CPU,直到它自己放弃。
-
Preemptive scheduling: a process can be preempted even though it could have happily continued executing.
抢占式,CPU 决定每个进程能跑多久,可以强制中止正在跑的进程。
操作系统中一般使用抢占式的(否则操作系统就不太需要做调度了)
Scheduling Decision Points¶
- When a process switches from the running state to the waiting state (for example, as the result of an I/O request or an invocation of wait() for the termination of a child process)
- When a process switches from the running state to the ready state (for example, when an interrupt occurs)
- When a process switches from the waiting state to the ready state (for example, at completion of I/O)
-
When a process terminates
-
Scheduling under 1 and 4 is nonpreemptive
- 2,3 preemptive
Scheduling Mechanisms¶
Scheduling Queues¶
- The Ready Queue contains processes that are in the READY state
- Device Queues contain processes waiting for particular devices
每个被等待的 devices 都有一个 device queues, 通过双向链表连接。

比如这里,我们将进程 2 运行,就将它从 ready queue 里拿出来。随后如果他要读硬盘,我们就把 PCB2 挂载到 disk unit 0 的 device queue 上。
Example

parent call fork 之后,子进程进入 ready queue。如果父进程使用了 wait,他就会被放到子进程的 waiting queue 里(实际上每个被等待的对象都有一个 waiting queue)。
当子进程拿到 CPU 时,它结束之后,操作系统会把父进程唤醒,随后父进程进入 ready queue。
当 CPU 再次被父进程拿到时,它会回收子进程这个 zombie。
Dispatcher¶
Dispatcher module gives control of the CPU to the process selected by the scheduler.
-
switching to kernel mode
kernel_entry, 用户态的信息存在pt_regs中。 -
switching context
上下文存在 PCB 中。
-
switching to user mode
- jumping to the proper location in the user program to restart that program
Dispatch latency 分发延时 – time it takes for the dispatcher to stop one process and start another to run.
这是 pure overhead,因为 CPU 没有做实际的工作。

Scheduling Algorithms¶
用下面的指标来衡量算法的好坏:
- CPU utilization – keep the CPU as busy as possible
- Throughput – # of processes that complete their execution per time unit
- Turnaround time – amount of time to execute a particular process
- Waiting time – amount of time a process has been waiting in the ready queue 可以是 arrival 之后没有执行,也可以是被抢占之后进入 ready queue
- Response time – amount of time it takes from when a request was submitted until the first response is produced, not output (for time sharing environment)

Scheduling Objectives
- Maximize CPU Utilization 最大化 CPU 利用率
- Maximize Throughput
- Minimize Turnaround Time 周转时间,指进程从创建到完成的时间。
- Minimize Waiting Time
- Minimize Response Time 响应时间,指进程从创建到第一次响应被接受的时间。
对于算法的选择
First-Come, First-Served Scheduling (FCFS)¶
Convoy effect - short process behind long process
慢车在快车后面,所有车都在后面等着。
- I/O-bound processes wait for the CPU-bound one
- 大大降低了利用率
example

Turnaround time = 0 + 24 + 27
Shortest-Job-First (SJF) Scheduling¶
When the CPU is available, it is assigned to the process that has the smallest next CPU burst 根据最小的下一次 CPU burst 决定,而不是整个 len
- 存在 starvation 低优先级的进程可能永远不会被运行
- Solution Aging – as time progresses increase the priority of the process
- SJF is provably optimal for average wait time
Proof (nonpreemptive version)
- 证明在一个长度递增的序列中,任何交互操作都会使得 waiting time 增加的幅度大于减少的幅度
分类
- 非抢占式 nonpreemptive
- 抢占式 preemptive Shortest-Remaining-Time-First | SRTF 根据剩余时间进行排序 if a new process arrives with CPU burst length less than remaining time of current executing process, preempt.
但我们执行一个任务之前,我们如何知道一个任务需要多长时间?(burst durations)
example
非抢占

抢占

注意计算 avg waiting time 时关注 arrival time 之后等待的时间
Predicting CPU burst durations¶
根据之前的时间,预测一个进程的下一次执行时间:$\tau_{n+1}=\alpha t_n + (1-\alpha)\tau_n$. 这个式子展开之后跟 AI 计算相关性的式子一样,越久远的记录贡献的比重越低

Priority Scheduling¶
优先级高的先被调度,优先级低的后被调度。(No convention: low number can mean low or high priority)
-
Priorities can be internal.
e.g. in SJF it’s the predicted burst time, the number of open files.
-
Priorities can be external.
e.g. set by users to specify relative importance of jobs.
为了实现优先级调度,我们可以使用优先队列来代替队列。
存在问题:优先级低的进程可能永远无法执行,即 starvation。
A solution: Priority aging
- Increase the priority of a process as it ages
Round-Robin Scheduling¶
RR Scheduling is preemptive and designed for time-sharing. 交互性更好
给进程一个固定时间片,用完了就跑到 ready queue 末尾排队。
Ready Queue is a FIFO. Whenever a process changes its state to READY it is placed at the end of the FIFO.
Scheduling:
- Pick the first process from the ready queue
- Set a timer to interrupt the process after 1 quantum
- Dispatch the process
-
No starvation, so better response time
在 SJF 中,如果不停的有时间短的进程进来,那么长进程就可能永远无法执行,称为 starvation。
-
The wait time is bounded.
- Trade-off
- Short quantum: great response/interactivity but high overhead
- Long quantum: poor response/interactivity, but low overhead
example

Multilevel Feedback Queues¶
一个队列里用一种调度方法,不同的队列里可以用不同调度方法。
- 每一种类的进程都分配一个 ready queue
- Scheduling within queues
- Each queue has its own scheduling policy
Processes can move among the queues.

Rationale: non-CPU-intensive jobs should really get the CPU quickly on the rare occasions they need them, because they could be interactive processes (this is all guesswork, of course).
非 CPU-intensive 的进程应该尽快得到 CPU,因为它们可能是交互式进程。
可以做的比较通用。
The Multilevel Feedback Queues scheme is very general because highly configurable
- 在不同的 queue中转移
Example

Real-Time Scheduling¶
什么是实时的调度系统?
在规定的时间内把给定的任务完成,而与执行时间长短无关(DDL)
- Hard real-time systems 一定要在指定的时间内完成,否则系统将会报错
- required to complete a critical task within a guaranteed amount of time
- Soft real-time computing 调度过程中定义一些 critical process 使重要的进程优先执行
- requires that critical processes receive priority over less fortunate ones
Thread Scheduling¶
Local Scheduling (Process-Contention Scope) – How the threads library decides which thread to put onto an available LWP
- 将 user kernel 和 system kernel 进行绑定
Global Scheduling (System-Contention Scope) – How the kernel decides which kernel thread to run next
-
process-contention scope (PCS)
每个进程分到时间片一样,然后进程内部再对线程进行调度。
-
system-contention scope (SCS)
所有线程进行调度。
现在主流 CPU 都是以线程为粒度进行调度的。
Multiple-Processor Scheduling¶
Multi-processor may be any one of the following architectures:
- Multi-core CPUs
- Multi-threaded cores
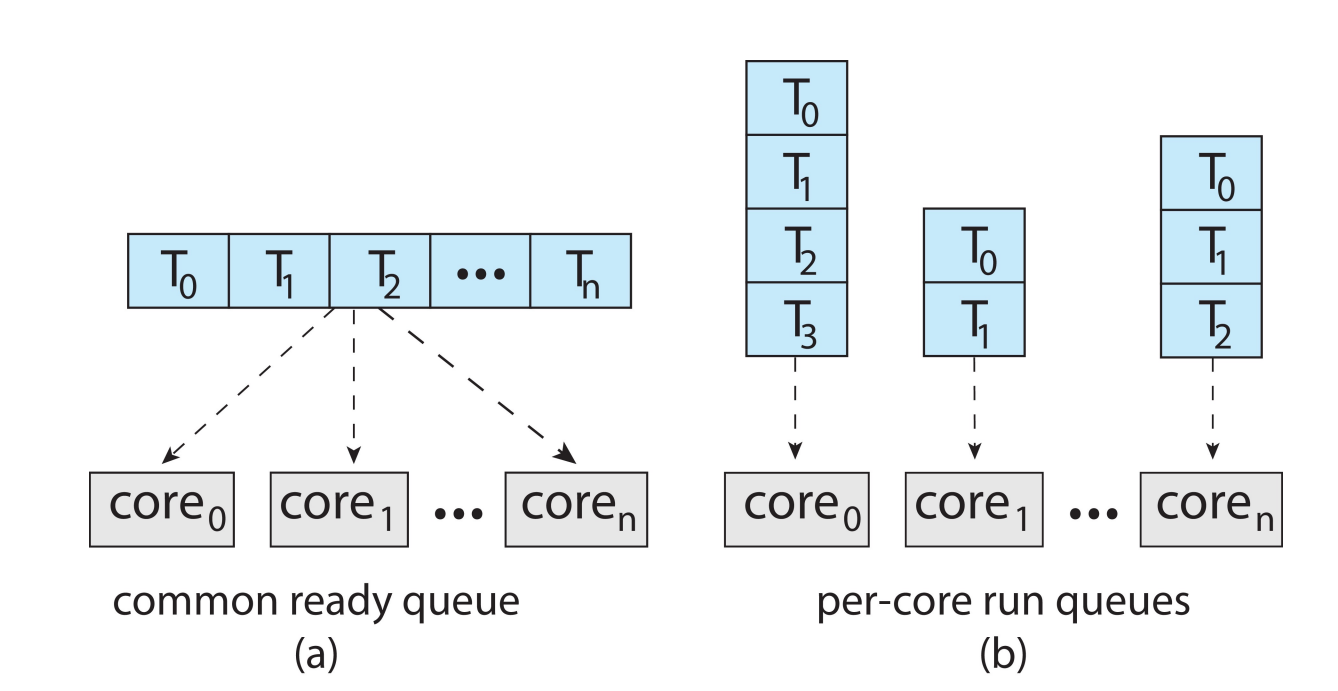
Multithreaded Multicore System¶
- All threads may be in a common ready queue (a)
-
Each processor may have its own private queue of threads (b)
现在大部分是这种架构。
CPU 中计算单元很快,但是内存访问是很慢的,需要 stall。为了利用这段 stall 的时间,我们就多用一个 thread,在这个 thread stall 时执行另一个 thread。(hyperthreading)

Chip-multithreading (CMT) assigns each core multiple hardware threads. (Intel refers to this as hyperthreading.)

hyperthreading 属于硬件线程,由硬件来调度,不同于 OS 里的 thread。
Multiple-Processor Scheduling¶
Load Balancing¶
- Load balancing attempts to keep workload evenly distributed
-
Push migration – periodic task checks load on each processor, and if found pushes task from overloaded CPU to other CPUs.
core 上工作太多,要推给其他的 core。
-
Pull migration – idle processors pulls waiting task from busy processor.
core 上工作太少,就从其他的 core 上拉一些任务过来。
Processor Affinity¶
有的进程我们想要在一个 core 上跑。
- Soft affinity – the operating system attempts to keep a thread running on the same processor, but no guarantees.
- Hard affinity – allows a process to specify a set of processors it may run on.
Linux Scheduling¶
- Nice command
- 数越小,优先级越高
ps -e -o uid,pid,ppid,pri,ni,cmd
Linux Scheduling: 0.11
Round-Robin + priority.
第一个红框 $O(N)$ 找 counter 最大的进程,如果 counter 不为 0 就执行,否则说明所有的进程都已经跑完自己的时间片了,重新赋值时间片,按照优先级赋值。(当时数越大,说明优先级越高,后来相反了)

每次找进程都要 $O(N)$,后来改为了 $O(1)$ 的算法(Linux 2.6)
The kernel keeps two arrays of round-robin queues
- One for active tasks: one Round Robin queue per priority level
- One for expired tasks: one Round Robin queue per priority level
每个优先级都对应一个数组,每个数组里有一个 Round Robin 队列。

struct prio_array {
int nr_active; // total num of tasks
unsigned long bitmap[5]; // priority bitmap
struct list_head queue[MAX_PRIO]; // the queues
}
The bitmap contains one bit for each priority level.
bitmap 存哪个优先级里还有元素,最开始所有位都是 0,如果有优先级里有进程,就把对应的位设为 1。找优先级最高的就是从左往右遍历,找到第一个 1 的位。x86 上正好有一个指令 bsfl(bit scan forward - from right to left)可以直接找到对应的位,然后再从对应的 task_list 取出一个进程。
prio_array.head_queue[bsfl(bitmap)].task_struct
一个任务执行完它的时间片后,就从 active array 移到 expired array。当 active array 为空时,就把 expired array 和 active array 交换。
问题在于:优先级数量受限制;而且 policy 和 mechanism 紧密绑定,难以维护,所以后来没有继续使用。
CFS: Completely Fair Scheduler
- Developed by the developer of $O(1)$, with ideas from others
- Main idea: keep track of how fairly the CPU has been allocated to tasks, and “fix” the unfairness
- For each task, the kernel keeps track of its virtual time
- The sum of the time intervals during which the task was given the CPU since the task started
- Could be much smaller than the time since the task started
- Goal of the scheduler: give the CPU to the task with the smallest virtual time. i.e., to the task that’s the least "happy"
Takeaway¶
-
There are many options for CPU scheduling
-
Modern OSes use preemptive scheduling
-
Some type of multilevel feedback priority queues is what most OSes do right now
-
A common concern is to ensure interactivity
-
I/O bound processes often are interactive, and thus should have high priority
-
Having “quick” short-term scheduling is paramoun